AI Agents vs. Chatbots: Why "Deflection" Is the Wrong Goal in 2026
AI agents resolve customer issues end-to-end; chatbots deflect them. The distinction matters because deflection metrics can look great while customers stay unhelped. Here's how to reframe your CX strategy around resolution rate.
AI Agents vs. Chatbots: Why "Deflection" Is the Wrong Goal in 2026
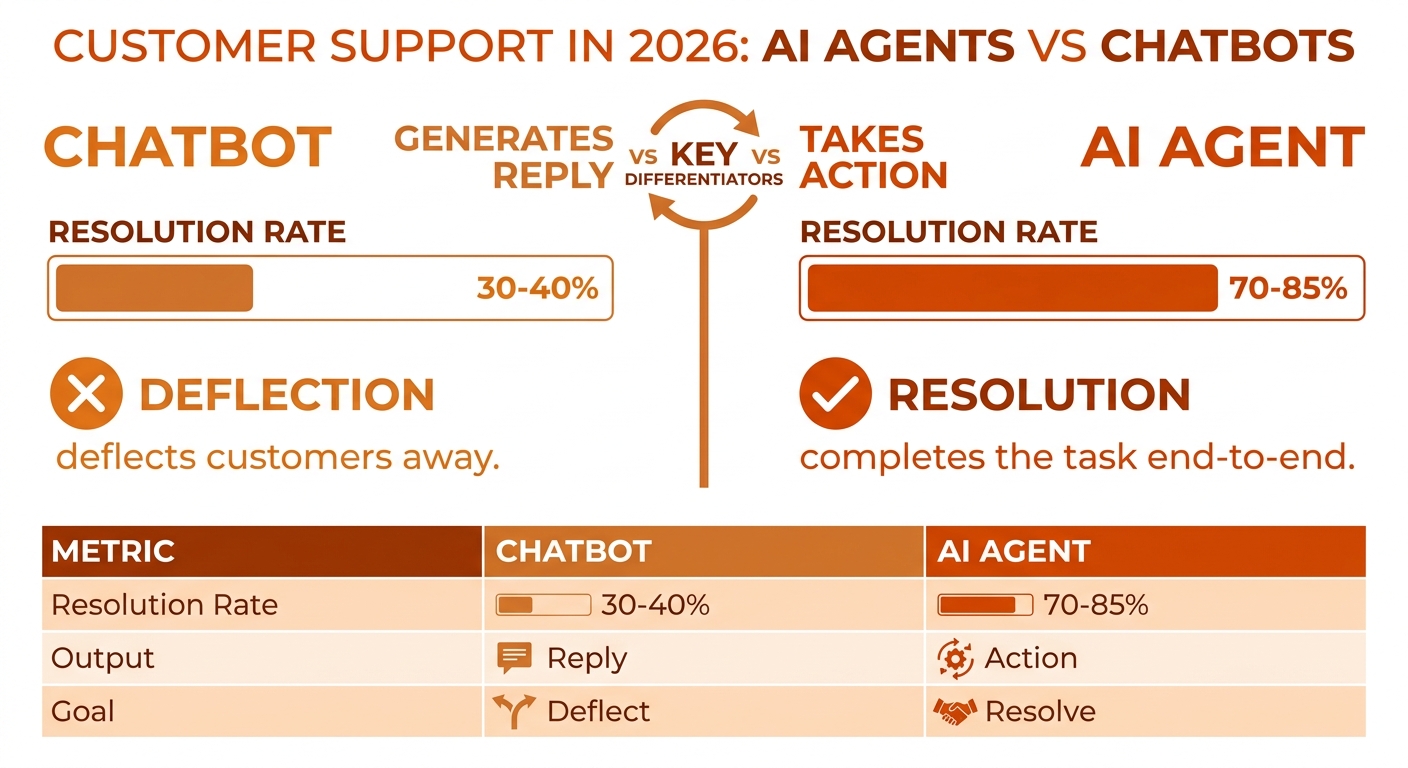
AI agents and chatbots are not the same category, and treating deflection as a success metric is the single most expensive mistake in e-commerce CX right now. AI agents resolve customer issues end-to-end by taking action across systems. Chatbots generate replies and route customers away from humans. The practical difference is a 30–45 percentage-point gap in resolution rate.
TL;DR: AI Agents vs. Chatbots at a Glance
| Dimension | Chatbot | AI Agent |
|---|---|---|
| Primary output | Reply (text) | Resolution (action) |
| Typical resolution rate | 30–40% | 70–85% |
| System access | None or read-only | Read + write across platforms |
| Decision logic | Rule-based scripts | SOP-encoded agent instructions |
| Escalation handoff | Routes to queue | Transfers with full context pre-filled |
| What it measures for success | Deflection rate | Resolution rate |
| What it leaves unresolved | Anything requiring action | Genuinely complex or escalation-flagged cases |
What Is the Difference Between an AI Agent and a Chatbot?
The functional difference comes down to whether the system can take action.
A chatbot receives a customer message, generates a reply, and closes the conversation. If a customer asks "where is my order?" a chatbot will paste the tracking link. If they ask "can I return this?" a chatbot explains the return policy. The customer reads the reply and still has to do something — click the link, initiate the return manually, or send another message when the reply doesn't match their specific situation.
An AI agent receives the same message and resolves the underlying task. It queries the Shopify order record and the carrier tracking API simultaneously, interprets the live status, sends an answer calibrated to that specific order, and closes the ticket — or, if the order is delayed past SLA, escalates with the full order context pre-filled in the agent note. The customer gets a resolved outcome, not an invitation to do more work.
This distinction — reply versus action — is what separates the two architectures. Chatbots are designed to deflect (route customers away from humans). Agents are designed to resolve (complete the job the customer wanted done).
Why Does "Deflection Rate" Mislead CX Leaders?
Deflection rate measures the percentage of customers who did not reach a human agent. At first glance, it looks like a cost metric — fewer humans touched, lower cost. CX teams have spent a decade optimizing for it, and vendors have spent just as long selling against it.
The problem: deflection captures customers who gave up, not just customers whose issues were solved.
Consider what actually happens when a chatbot "deflects" a contact:
- The customer finds the answer. This is genuine deflection — the issue was resolved without an agent. This is maybe 25–30% of deflected contacts.
- The customer gives up and waits. They didn't reach a human because the chatbot presented a dead end, and frustration wasn't worth the effort of escalating. The issue goes unresolved. They may or may not come back.
- The customer sends a second ticket. They submitted the chatbot form, got an answer that didn't apply to their situation, and tried again. This one reaches a human — except now the agent is handling a second, angrier version of the same contact.
- The customer leaves entirely. This is the invisible outcome. The customer churned, disputed a charge, or posted a negative review. No second contact, no CSAT survey, no record in your deflection denominator.
A 70% deflection rate can hide a 30% re-contact rate, a 3.2/5 CSAT on chatbot interactions, and a measurable increase in chargebacks after peak season. None of those appear in the deflection metric. The metric is technically correct and strategically misleading.
The alternative — SOP-driven AI automation — measures resolution rate: the percentage of contacts where the underlying customer job was actually completed. Resolution compounds; deflection leaks.
What Does the Resolution Rate Gap Actually Look Like?
The data is consistent across independent sources:
Rule-based chatbots and FAQ bots resolve 30–40% of contacts without human intervention. This ceiling is structural: they can only respond to queries that match a pre-defined script or knowledge base entry. When a customer's situation doesn't match the script — a delayed shipment, a partial fulfillment, a discount code that didn't apply correctly — the bot generates a generic response or routes to a human.
AI agents with system access resolve 70–85% of tier-1 contacts. The range reflects the quality of underlying SOP encoding and the breadth of system integrations: an agent that can read Shopify, write to Gorgias, and query a carrier API resolves more than one that can only read a knowledge base. Intercom's published data shows its Fin agent resolving 67% of contacts across over 40 million conversations — a concrete real-world benchmark at the bottom of the AI-agent range.
Gartner's March 2025 forward estimate: Senior Director Analyst Daniel O'Sullivan projects that by 2029, agentic AI will autonomously resolve 80% of common customer service issues without human intervention, leading to a 30% reduction in operational costs. That projection assumes AI agents, not chatbots — the word "autonomously resolve" is doing real work here.
The 30–45 point resolution gap is not a marginal improvement. At 10,000 contacts per month: a chatbot resolves 3,500–4,000 without a human; an AI agent resolves 7,000–8,500. The extra 3,500–4,500 resolved contacts represent hours of agent time, CSAT points, and re-contact rate. At $3–$13 per assisted contact (Gartner's per-channel cost benchmarks), the economic delta per month is substantial even for mid-market teams.
Why Are Chatbots Structurally Limited to Deflection?
Most helpdesk chatbots are designed to live inside a single platform and respond within that platform's data model. A Gorgias chatbot can read Shopify order data because Gorgias has a Shopify integration — but it cannot write back to Shopify, query a carrier API, update a CRM record, or trigger a refund workflow. It is a read-only response generator inside one platform's wall.
This architecture produces the deflection ceiling:
- No system writes. A chatbot that can tell a customer their package is late cannot rebook the shipment, file a claim, or issue a store credit. The action requires a human.
- Single-platform scope. When the resolution requires data from two systems (Shopify order + carrier tracking) or an action in one system (close ticket in Gorgias) confirmed in another (log in Salesforce), the chatbot cannot close the loop.
- Script-bound decision logic. Scripts cover the common cases. They do not adapt to the edge cases — the order with two partial fulfillments, the customer who emailed twice already, the shipment at an unfamiliar regional hub. Edge cases go to humans.
- No escalation intelligence. When escalation happens, the chatbot drops the customer into a queue with the conversation transcript. The agent must reconstruct context — re-read the messages, re-query the order, re-check the carrier — before they can type a word. Handle time goes up, not down.
These are not bugs. They are features of the deflection architecture: the chatbot's job is to keep customers out of the queue. Resolution was never the design goal.
What Does an AI Agent Do That a Chatbot Cannot?
The architecture of a resolution-first AI agent inverts the chatbot's limitations at each layer.
System access is read-write across platforms. The agent authenticates into Shopify, the carrier API, the helpdesk, and any other system in the workflow. It does not just read — it can issue a refund, generate a return label, update the ticket status, log the interaction, and confirm the action back to the customer in a single pass. See the WISMO automation decision framework for a concrete example of what this looks like for order-status tickets.
SOP-encoded decision logic replaces scripts. Instead of scripted response trees, the agent works from a Standard Operating Procedure: a set of rules that encodes what the right action is for each situation. SOPs handle edge cases because they express conditional logic ("if the order is above $300 AND the carrier shows no movement for 72 hours, escalate with context pre-filled") rather than simple trigger-response pairs.
Guardrails define what stays human. Resolution-first agents don't try to automate everything. They have guardrails — pre-defined conditions that route a ticket to a human: high order value, fraud flags, carrier-reported loss, SLA breach. The agent evaluates these before acting. The human queue becomes genuinely exception-only.
Escalation handoffs are structured. When a ticket does escalate, the agent writes a structured summary — customer name, order ID, full status from every connected system, prior interaction history, guardrail that triggered — into the helpdesk ticket before the human agent opens it. Handle time on escalated tickets drops even though the human is now handling a harder problem, because they never start cold.
How Do Resolution-First Metrics Change What You Measure?
Switching from deflection to resolution means tracking different numbers — and tracking them together:
Containment rate (percentage of contacts resolved without human escalation) replaces deflection rate. The numerator is contacts that were resolved — action completed, customer confirmed — not contacts that didn't reach a human.
Re-contact rate (customers who submit a second contact on the same issue within 72 hours) cross-validates containment. A high containment rate paired with a high re-contact rate reveals deflection masquerading as resolution. A high containment rate with a low re-contact rate confirms genuine resolution.
CSAT on auto-resolved vs. agent-resolved tracks whether autonomous resolution delivers quality parity with human agents. World-class AI agents achieve CSAT scores within 2–3 points of human agents on tier-1 contacts; below that threshold, the SOP configuration needs work.
Cost per resolved contact (total support cost ÷ contacts resolved, whether by human or agent) gives the true unit economics. Compare this across your handled-by-human vs. handled-by-agent cohorts to find where automation is actually saving money and where it is creating re-contact cost.
For the full metric framework and benchmarks, see the 11-strategy ranked guide to reducing Shopify support tickets, which covers how these metrics interact at the ticket-volume level.
What Should E-commerce CX Leaders Do With This?
The practical reframe for 2026 has three steps.
First, audit what your current chatbot is actually deflecting. Pull your re-contact rate for chatbot-handled contacts from the last 90 days. If more than 15% of contacts that the chatbot "deflected" come back as a second ticket within 72 hours, you have a deflection metric hiding a resolution problem. That number is your improvement ceiling.
Second, identify the highest-volume ticket types that require action, not just information. WISMO tickets, return initiations, refund requests, address changes — these are not information requests. A customer asking "where is my order?" does not need a paragraph; they need to know exactly what is happening with their specific order, right now. If your current chatbot cannot issue a refund, initiate an RMA, or query live carrier status, it cannot resolve these. It can only deflect them.
Third, pilot an agentic layer on one ticket type before committing to a full replacement. The common mistake is treating "AI agent" as a rip-and-replace decision for the entire support stack. It is not. CorePiper's architecture layers on top of whatever helpdesk you already run — Gorgias, Zendesk, Freshdesk, Salesforce — and handles the resolution logic across your systems without replacing the platform your team uses. Start with WISMO, measure containment rate and re-contact rate for 30 days, and let the data make the case for expanding scope.
The Gartner 80%-by-2029 projection is not a passive prediction. It is a competitive benchmark: the teams that get to 80% autonomous resolution before their competitors do are not waiting until 2029. They are running agentic layers now, measuring resolution rate instead of deflection rate, and treating every chatbot-generated non-resolution as a cost center — not a success.
The Bottom Line
Chatbots and AI agents solve different problems for different architectures. If your goal is to keep customers out of the human queue regardless of whether their issue gets resolved, a chatbot optimizes for that goal. If your goal is to resolve customer issues without human labor — actually completing the job, issuing the refund, changing the address, closing the ticket — an AI agent is the right architecture.
In 2026, deflection is no longer a defensible success metric for e-commerce CX. Customers expect completion, not communication. Measuring resolution — and building the systems that make it achievable — is the lever that compounds.
Book a demo to see how CorePiper's SOP-driven agents resolve tier-1 tickets end-to-end across Shopify and your existing helpdesk — and how to measure the difference from day one.
Stop Measuring Deflection. Start Measuring Resolution.
CorePiper's SOP-driven agents resolve order, returns, and shipping tickets end-to-end across Shopify, Zendesk, Gorgias, and your carrier portals — taking real action, not just generating replies. Book a 30-minute walkthrough to see what resolution-first support looks like.