What Is First Contact Resolution (FCR)? Benchmarks + How to Improve It
First Contact Resolution (FCR) is the percentage of customer issues resolved in a single interaction. The industry average is 70%; world-class is 80%+. FCR is the strongest single predictor of CSAT — here's how to measure it and move it.
What Is First Contact Resolution (FCR)? Benchmarks + How to Improve It
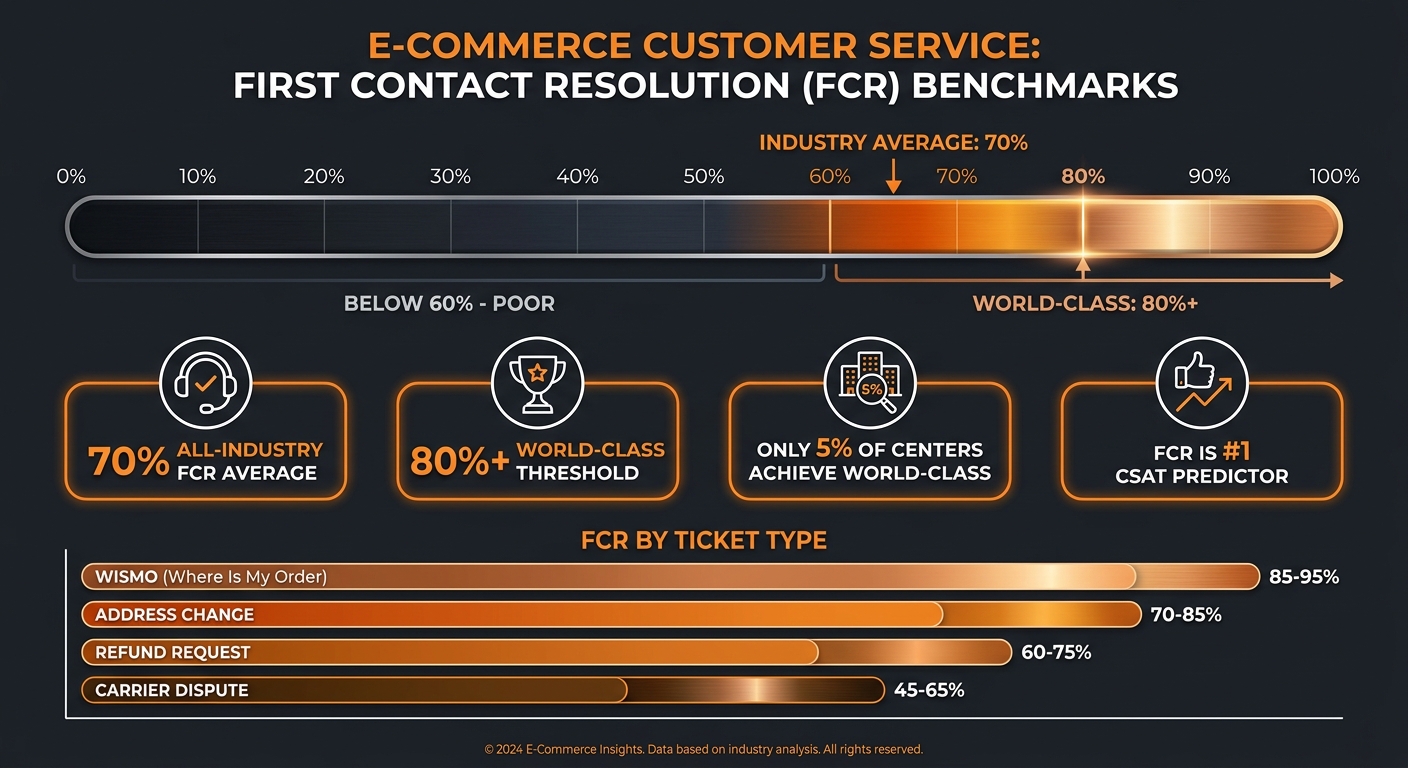
First Contact Resolution (FCR) is the percentage of customer service issues resolved in a single interaction without requiring a follow-up contact. Per SQM Group's benchmark research, the all-industry FCR average is 70%; world-class is 80%+, reached by roughly 5% of contact centers. FCR is the single strongest predictor of CSAT — and the metric that separates genuine AI resolution from chatbot deflection.
TL;DR: FCR Benchmarks at a Glance
| FCR Level | Rate | What It Signals |
|---|---|---|
| World-class | 80%+ | Only ~5% of centers; strong automation + SOP discipline |
| Industry average | 70% | Standard for well-run contact centers |
| Below average | Below 60% | Structural gaps: system access, decision logic, or handoff design |
| Chatbot deflection baseline | 30–40% | Typical for rule-based chatbots without system access |
| AI agent (SOP-driven) | 70–85% | When AI can access systems and take action |
What Does First Contact Resolution Actually Mean?
FCR counts an interaction as a "resolution" when the customer's issue is fully addressed in that single interaction and the customer does not contact support again about the same issue within a measurement window — typically 7 or 30 days.
The definition has two elements that matter operationally:
1. "Single interaction" scope. FCR is measured per channel and per ticket type. A WISMO ticket resolved via an AI chat in one session is a 1-contact resolution. The same ticket that required a chat, then a follow-up email, then a phone call to close is three contacts — only one of which can be an FCR if the last contact resolves it.
2. "Not contacted again" threshold. Most operations define the measurement window at 7 days (same issue, same customer, re-contacting). Some use 30 days for more complex ticket types (freight claims, return disputes). Shorter windows miss the customer who waited a week before calling back; longer windows overcount re-contacts for genuinely separate issues.
The most common FCR measurement error is counting tickets that were closed rather than tickets that were resolved — these are not the same. A ticket can be closed (marked done in Zendesk, Freshdesk, or Gorgias) while the underlying issue was not fixed. FCR requires pairing the closed ticket with a confirmation that the customer did not re-open or re-contact about the same issue. Without that second data point, you are measuring closure rate, not resolution rate.
What Is a Good FCR Rate? 2026 Benchmarks by Channel and Ticket Type
Per SQM Group's benchmarks, which cover over 500 contact centers across industries, the FCR distribution looks like this:
| FCR Performance Tier | FCR Rate | % of Contact Centers |
|---|---|---|
| World-class | 80%+ | ~5% |
| Above average | 75–79% | ~15% |
| Average | 70–74% | ~35% |
| Below average | 60–69% | ~30% |
| Poor | Below 60% | ~15% |
For e-commerce specifically, FCR benchmarks vary sharply by ticket type because the data access requirements, decision complexity, and action requirements are entirely different:
| Ticket Type | FCR Range (Human Agent) | FCR Range (Automated AI) |
|---|---|---|
| WISMO / order status | 80–90% | 85–95% |
| Address change or order edit | 65–80% | 70–85% |
| Refund or return request | 55–70% | 60–75% |
| Damaged item / carrier claim | 45–65% | 50–70% |
| Fraud or chargeback dispute | 40–60% | 30–50% |
| Subscription / account issue | 50–65% | 55–70% |
Two patterns in this table matter for operational decisions:
First, WISMO and order-status tickets — the highest-volume category in e-commerce at 30–50% of all inbound — are also the most automatable and have the highest achievable FCR. If you are not starting your FCR improvement effort with WISMO, you are starting in the wrong place.
Second, AI agents do not always outperform human agents on FCR by ticket type — they do on WISMO (because the lookup-and-answer loop is fast and deterministic) but lag on fraud cases (because fraud detection requires judgment that rule-based automation handles poorly). The FCR gap between human and AI narrows or reverses on tickets requiring nuanced, context-dependent decisions. This argues for hybrid designs: AI handles the volume tiers (WISMO, standard refunds, routine address changes) and humans handle the complex tiers (disputes, fraud, high-value exceptions).
Why Is FCR the Strongest CSAT Predictor?
SQM Group's research — the most cited longitudinal dataset in contact center benchmarking — found that achieving first-contact resolution is the single strongest predictor of a positive CSAT score, outranking speed, channel, and agent friendliness.
The mechanism is effort. Gartner's Customer Effort Score research found that high-effort interactions are 4× more likely to create a disloyal customer than low-effort ones. Every re-contact increases effort. A customer who resolves in one contact experienced low effort. A customer who contacts three times — even if ultimately resolved — experienced high effort and is at elevated churn risk regardless of how friendly each interaction was.
The correlation is directional: for every 1% improvement in FCR, CSAT improves roughly 1.0–1.2 percentage points per SQM Group's benchmarks. That means moving FCR from 65% to 75% — a 10-point improvement — is worth approximately 10–12 points of CSAT improvement without any other change to support quality, pricing, or product.
The practical implication: if you are trying to improve CSAT and your FCR is below the industry average, fixing FCR is a higher-leverage intervention than CSAT coaching, survey optimization, or agent sentiment training. Those interventions may move CSAT 1–2 points at best. FCR improvement of 10 points moves it 10–12.
How Is FCR Calculated?
The standard formula:
FCR Rate = (Tickets Resolved in One Contact / Total Tickets) × 100
In practice there are two measurement methods with meaningfully different operational implications:
Customer-defined FCR (preferred). Survey customers after contact: "Was your issue fully resolved today?" Cross-reference customers who answer "yes" against re-contact records to confirm they did not contact again within 7–30 days. This is the most accurate FCR measure because it captures the customer's own perception of resolution.
System-defined FCR. Flag tickets as resolved and measure what percentage of resolved tickets were not re-opened within the measurement window. This is faster to implement but systematically overstates FCR because it counts "tickets closed without re-open" rather than "issues resolved without re-contact" — customers who gave up, switched channels, or submitted a new ticket about the same issue are excluded from the denominator.
For e-commerce support operations, the most practical implementation:
- Tag each ticket with a ticket type and issue category at open
- Set a 7-day re-contact window per ticket type (extend to 30 days for complex types like return disputes)
- Flag any re-contact within the window that references the same order, same issue category, or same original ticket as a FCR failure
- Report FCR separately by ticket type, channel, and — where possible — by automation path (human vs. AI agent) to identify where the gaps are
The segmentation by automation path is what separates diagnostic FCR measurement from tracking a single aggregate number. A blended 68% FCR rate tells you you're below average. A breakdown showing 92% FCR on automated WISMO, 71% on AI-assisted refunds, and 51% on human-handled carrier disputes tells you exactly where to invest.
What Causes Low FCR Rates in E-commerce?
Four root causes account for the majority of low-FCR situations in e-commerce support:
1. No system access at resolution time. The single largest driver of re-contacts in e-commerce is an agent (human or AI) that can answer a question but cannot take the action required to close the issue. A customer asking "where is my order" who receives the answer "your package is delayed until Wednesday" is not resolved — the ticket re-opens when Wednesday passes and there's still no delivery. Resolution requires the action (proactive notification, replacement shipment, refund trigger) not just the answer.
2. Ticket routing to the wrong agent or automation. Complex WISMO tickets (delivered-but-missing, exception codes, carrier disputes) get routed into the same WISMO queue as simple status checks and handled by the same automation. The simple checks resolve at 95%. The complex ones fail and re-contact. Undifferentiated routing treats them the same, averaging the FCR down and masking the problem.
3. Incomplete SOPs with edge cases unhandled. A refund policy that says "approve refunds under $50" leaves the agent — human or AI — without direction on what to do for a $50.01 item. The ticket gets held, escalated, or closed with a "we'll follow up" response, generating a re-contact when the customer checks back in 48 hours. SOP-driven resolution explicitly handles edge cases so the resolution logic doesn't stall at boundaries.
4. Single-system tooling in a multi-system world. A support agent working inside Zendesk who cannot see the Shopify order, the carrier tracking API response, or the payment gateway record has to manually cross-reference three systems before taking action. Each system-switch is a failure point: copy-paste errors, stale data, time pressure leading to premature closure. Multi-system access — Shopify + helpdesk + carrier + payment in one workflow — removes the structural friction that causes agents to close tickets before fully resolving them.
How Do AI Agents Improve FCR Compared to Chatbots?
The FCR gap between AI agents and chatbots is structural, not incremental:
| Tool Type | Typical E-commerce FCR | Why |
|---|---|---|
| Rule-based chatbot | 30–40% | Can answer questions; cannot access systems or take action |
| AI chatbot (LLM, no tools) | 40–55% | Better answers; still cannot execute actions without integrations |
| AI agent (SOP-driven, with system access) | 70–85% | Takes action across Shopify, helpdesk, carrier, and payment systems |
The reason chatbots — including LLM-based chatbots without tool access — land at 30–55% FCR in e-commerce is not that the AI is wrong. It is that answering the question is not the same as resolving the issue. A customer asking "where is my order" whose chatbot answers "your package is in transit with a delivery estimate of Friday" has received an accurate answer. But if Friday passes and the package doesn't arrive, they are back in the queue — and that interaction was not an FCR.
An AI agent with the right integrations handles the same scenario by:
- Looking up the live carrier status (not just the tracking page — the full event feed including exceptions)
- Applying the SOP: if exception code X, trigger proactive email + set up auto-notify; if exception code Y, file a claim; if delayed but on track, send updated estimate with a discount code
- Taking that action in the same interaction and closing the ticket
The customer does not contact again because the issue was actually resolved. That is what moves FCR from the 40s into the 70–85% range — not better copy, not a more empathetic response, but completing the action the customer needed.
What Is the FCR Impact of Cross-Platform Resolution?
For e-commerce brands using multiple systems — Shopify for orders, Zendesk or Freshdesk for support, Salesforce for accounts, and carrier APIs for tracking — FCR improvement requires cross-platform action-taking, not single-helpdesk optimization.
The limitation of single-helpdesk AI tools (Zendesk AI, Gorgias AI Automate, Intercom Fin configured for one platform) is that they are bounded by the data and action surface of their native system. Zendesk AI can look up ticket history. It cannot read the Shopify order, check the carrier API, or update the Salesforce account — unless a custom integration is built and maintained for each connection.
For tickets that require a multi-system sequence — order lookup → carrier status → refund decision → Shopify refund trigger → helpdesk ticket closure — single-system tools create gaps at each handoff. Those gaps generate re-contacts (the customer got the Zendesk response but the refund didn't process) that pull FCR down.
CorePiper's SOP-driven approach connects the action-taking layer across Shopify, Zendesk, Freshdesk, Salesforce, and carrier APIs so that a single ticket can read from and write to all of them. That removes the handoff gaps that cause re-contacts on multi-system issues — and closes the structural FCR gap for the ticket types where cross-platform action is required.
How to Improve FCR: A Prioritized Action List
Based on where the FCR gaps concentrate in e-commerce operations:
1. Start with WISMO — it is the highest-volume, highest-FCR opportunity. WISMO tickets make up 30–50% of e-commerce support volume. Fully automated WISMO resolution (carrier API lookup + decision logic + action in one pass) reaches 85–95% FCR. Improving this single ticket type from 75% to 90% FCR across 500 monthly WISMO tickets eliminates 75 re-contacts per month.
2. Audit your re-contacts by ticket type to find where FCR actually breaks. Do not optimize a blended FCR number — segment it. The 45–65% FCR range on carrier disputes is not the same problem as the 85%+ on automated WISMO. Segment, find the lowest FCR ticket types with the highest volume, and fix those first.
3. Ensure every SOP has explicit edge case handling. The most common FCR failure point is an SOP that covers the 80% case and leaves the 20% edge cases unhandled. When an AI agent or human hits an unhandled edge case, it either stalls or gives an answer that doesn't resolve the issue. Audit SOPs for boundary conditions (dollar thresholds, exception codes, product categories, customer segments) and add explicit handling for each.
4. Give your automation access to the systems it needs to take action — not just to answer questions. FCR requires completing the action, not describing what the action would be. If your AI support tool can describe the refund policy but cannot trigger the refund, it will not improve FCR on refund tickets. Map your ticket types to the systems they touch and ensure your automation can read and write to all of them.
5. Measure FCR separately by automation path. If you cannot see human FCR vs. AI FCR by ticket type, you cannot improve either one deliberately. Instrument your ticketing system to tag resolution path and measure re-contacts per path to get actionable signal.
Frequently Asked Questions
What is First Contact Resolution (FCR)?
First Contact Resolution (FCR) is the percentage of customer service issues resolved in a single interaction, without requiring the customer to contact support again about the same issue. It is measured per channel (phone, email, chat, AI) and per ticket type, and is the strongest single predictor of customer satisfaction (CSAT) in contact center research.
What is a good FCR rate in 2026?
Per SQM Group's benchmarks, the all-industry FCR average is 70%. World-class FCR — 80% or higher — is achieved by approximately 5% of contact centers. For e-commerce, FCR benchmarks vary by ticket type: WISMO and order-status tickets reach 85–95% FCR when fully automated, while complex carrier disputes or fraud cases may run 45–65% even with skilled human agents.
What is the difference between FCR and resolution rate?
FCR measures whether an issue was resolved in a single interaction — it is a contact-level metric. Resolution rate (also called containment rate) measures whether a ticket was resolved at all without human escalation — it is a ticket-level metric. An AI agent can have a high resolution rate but a lower FCR if customers needed to follow up once after the initial automation. For e-commerce operations, both metrics are necessary: resolution rate shows automation coverage; FCR shows whether that resolution stuck.
Why does FCR predict CSAT so strongly?
SQM Group's longitudinal research across thousands of contact center interactions found that resolving an issue on first contact is the single largest driver of customer satisfaction — more predictive than speed, channel, or agent friendliness. The mechanism is effort: customers who need to contact support twice or more experience significantly higher effort, and high-effort interactions are 4× more likely to create disloyal customers per Gartner's Customer Effort Score research.
How do AI agents improve FCR compared to chatbots?
Rule-based chatbots typically achieve 30–40% resolution rates on e-commerce tickets — well below the 70% industry FCR average — because they can answer questions but cannot access systems, execute actions, or apply conditional logic. SOP-driven AI agents that connect to Shopify orders, carrier APIs, helpdesk history, and payment systems achieve 70–85% resolution rates by completing the action in the same interaction, not passing a ticket back to a human queue.
CorePiper's SOP-driven agents are built to improve FCR on the ticket types where it breaks — WISMO, refunds, carrier claims, order edits — by connecting the action-taking layer across Shopify, Zendesk, Freshdesk, Salesforce, and carrier APIs. The benchmark you're aiming for is 80%+. The path to it is resolution, not deflection. Book a demo to see how the FCR numbers shift when the automation can actually close the loop.
Move the Metric That Moves Everything Else
CorePiper's SOP-driven agents improve FCR by giving AI the system access, decision logic, and action-taking capability to resolve tickets in one pass — not draft a response and hope. See the difference on your actual ticket types. Book a 30-minute walkthrough.